大模型应用开发入门:掌握Transformer Embedding与向量表示,轻松收藏提升技能!
2026/4/14 14:53:11
10分钟阅读

Transformer Embedding 与向量表示Embedding嵌入/向量表示是将离散的文本数据转换为连续向量空间中的数值表示的核心技术使得计算机能够「理解」语义信息。本篇覆盖词向量的基本原理、位置编码Positional Encoding的作用与演进、语义相似度计算方法以及Embedding 在 RAG 系统和向量数据库中的实际应用。概念速览一、词向量Word Embedding文本的数值化表示1.1 为什么需要词向量计算机无法直接处理文字只能处理数字。如何让机器「理解」文本的含义这就需要将文字转换为数值形式。通俗理解想象你要向一个只懂数学的外星人解释「苹果」和「香蕉」的关系。你不能说「它们都是水果」因为外星人不懂「水果」这个词。但你可以说「苹果的坐标是 (3, 5, 2)香蕉的坐标是 (3.2, 4.8, 2.1)它们在空间中很近说明它们相似。」这就是词向量的核心思想——用数字坐标表示词义。1.2 从 One-Hot 到 Word Embedding 的演进早期方案One-Hot 编码最简单的文本数值化方式是 One-Hot 编码词汇表[苹果, 香蕉, 汽车, 飞机]苹果 → [1, 0, 0, 0]香蕉 → [0, 1, 0, 0]汽车 → [0, 0, 1, 0]飞机 → [0, 0, 0, 1]One-Hot 的致命缺陷维度灾难词汇表有 10 万个词每个词就是 10 万维的向量语义缺失「苹果」和「香蕉」的向量完全正交无法体现「都是水果」的语义关系稀疏表示向量中绝大多数是 0计算效率低Word Embedding 的突破Word Embedding 将每个词映射到一个低维稠密向量通常 100-1000 维并且语义相近的词在向量空间中距离更近。1.3 Word Embedding 的工作原理核心思想分布式假设「一个词的含义由它的上下文决定。」——如果两个词经常出现在相似的上下文中它们的语义就相近。通俗理解如果你在阅读时总是看到「猫追着老鼠跑」「狗追着老鼠跑」即使你不知道「猫」和「狗」的具体含义你也能推断它们有某种相似性——它们都能「追老鼠」。Word Embedding 就是用数学方法捕捉这种「上下文相似性」。Embedding 层的数学表示Embedding 层本质上是一个查找表Lookup Table# 假设词汇表大小 V10000嵌入维度 d512embedding_matrix torch.randn(10000, 512) # 形状(V, d)# 查找词 苹果 的向量假设索引为 42apple_vector embedding_matrix[42] # 形状(512,) 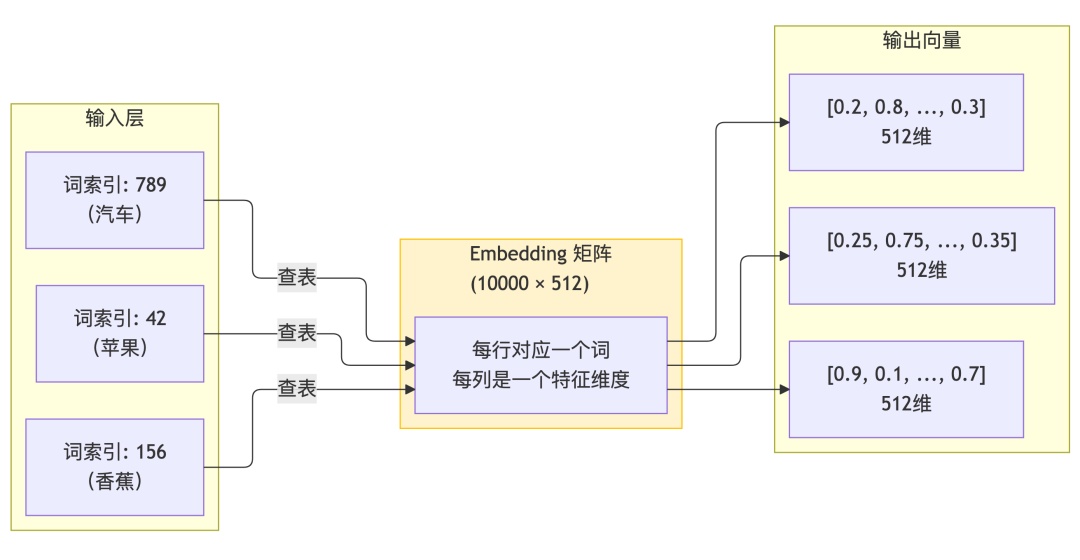 ### 1.4 词向量的语义特性 训练好的词向量具备以下语义特性 **1. 语义相似性** 语义相近的词在向量空间中距离更近 plaintext cos_similarity(苹果, 香蕉) ≈ 0.85 # 都是水果cos_similarity(苹果, 汽车) ≈ 0.12 # 毫无关联2. 语义类比向量运算著名的「国王 - 男人 女人 ≈ 女王」vector(国王) - vector(男人) vector(女人) ≈ vector(女王)通俗理解这说明词向量捕捉到了「性别」这个维度。「国王」减去「男性特征」再加上「女性特征」得到的向量最接近「女王」。二、位置编码Positional Encoding让模型理解词序2.1 为什么需要位置信息Transformer 的 Self-Attention 机制有一个关键问题它对词的顺序是「盲」的。通俗理解对于 Self-Attention 来说「狗咬人」和「人咬狗」是一样的——都是「狗」「咬」「人」三个词的集合。但这两句话的意思完全相反所以必须给模型注入位置信息。2.2 绝对位置编码正弦余弦位置编码原始 Transformer 论文使用正弦/余弦函数生成位置编码公式其中•pos是词在序列中的位置0, 1, 2, …•i是向量的维度索引•d_model是嵌入维度如 512通俗理解想象一个钟表秒针转得快、分针转得慢、时针转得更慢。位置编码的不同维度就像不同的「指针」转动频率不同。通过观察所有「指针」的位置你能唯一确定当前时间。同样通过所有维度的正弦余弦值模型能唯一确定每个词的位置。为什么用正弦余弦值域有界输出在 [-1, 1] 之间不会过大可泛化对任意长度的序列都能生成编码相对位置可计算PE(posk)可以表示为PE(pos)的线性函数2.3 旋转位置编码RoPE当前主流方案版本说明RoPERotary Position Embedding由苏剑林于 2021 年提出现已成为 LLaMA、Qwen、GLM 等主流大模型的标准配置。RoPE 的核心思想RoPE 不是简单地「加上」位置信息而是通过旋转的方式将位置信息编码到 Query 和 Key 中。通俗理解想象你在一个旋转木马上位置 0 的马朝向北方位置 1 的马旋转了 30 度朝向东北位置 2 的马又旋转了 30 度…每匹马的方向就编码了它的位置信息。RoPE 就是让词向量像旋转木马一样通过旋转角度来编码位置。RoPE 的优势2.4 位置编码的实际应用在 Transformer 中的使用方式# 伪代码位置编码的使用def transformer_input(tokens): # 1. 词嵌入 word_embeddings embedding_layer(tokens) # (batch, seq_len, d_model) # 2. 位置编码 positional_encodings get_positional_encoding(seq_len, d_model) # 3. 相加传统方式 input_embeddings word_embeddings positional_encodings return input_embeddings三、语义相似度向量空间中的距离度量3.1 余弦相似度最常用的相似度度量公式通俗理解余弦相似度衡量的是两个向量的「方向」是否一致而不关心它们的「长度」。想象两个人同时指向天空的同一颗星星无论他们站得多远他们指向的方向是一致的余弦相似度就是 1。取值范围•1完全相同方向最相似•0完全正交无关•-1完全相反方向最不相似3.2 其他相似度度量方法余弦相似度只关注方向不关注长度适用于文本语义相似度点积相似度同时考虑方向和长度适用于 Attention 计算欧氏距离绝对距离适用于聚类分析曼哈顿距离格点距离适用于高维稀疏向量3.3 相似度计算的代码实现import numpy as npdef cosine_similarity(vec_a, vec_b): 计算两个向量的余弦相似度 dot_product np.dot(vec_a, vec_b) norm_a np.linalg.norm(vec_a) norm_b np.linalg.norm(vec_b) return dot_product / (norm_a * norm_b)# 示例embedding_apple np.array([0.2, 0.8, 0.3, 0.5])embedding_banana np.array([0.25, 0.75, 0.35, 0.48])embedding_car np.array([0.9, 0.1, 0.7, 0.2])print(f苹果-香蕉相似度: {cosine_similarity(embedding_apple, embedding_banana):.4f}) # ≈ 0.98print(f苹果-汽车相似度: {cosine_similarity(embedding_apple, embedding_car):.4f}) # ≈ 0.45四、Embedding 模型与 API 实践4.1 主流 Embedding 模型对比版本说明以下信息截至 2026 年 3 月OpenAI 已发布 text-embedding-3 系列模型智谱 AI 已发布 embedding-3 模型通义千问已发布 Qwen3-Embedding 系列API 名称 text-embedding-v4。4.2 OpenAI Embedding API 使用示例from openai import OpenAIclient OpenAI()def get_embedding(text, modeltext-embedding-3-small): 获取文本的 Embedding 向量 response client.embeddings.create( inputtext, modelmodel ) return response.data[0].embedding# 使用示例text Transformer 是现代大语言模型的核心架构embedding get_embedding(text)print(f向量维度: {len(embedding)}) # 1536print(f前5个值: {embedding[:5]})4.3 Embedding 维度选择策略text-embedding-3 系列支持维度缩放Matryoshka Embedding可根据需求选择合适维度# 指定输出维度response client.embeddings.create( inputHello world, modeltext-embedding-3-large, dimensions256 # 可选256, 512, 1024, 3072)五、向量数据库与 RAG 应用5.1 向量数据库概述向量数据库是专门为存储和检索高维向量设计的数据库系统是 RAG检索增强生成系统的核心基础设施。5.2 主流向量数据库对比5.3 RAG 检索流程详解5.4 Embedding 在 RAG 中的最佳实践1. 文档切分策略# 推荐的切分参数CHUNK_SIZE 512 # 每块的 Token 数CHUNK_OVERLAP 50 # 块之间的重叠 Token 数2. 检索优化技巧•混合检索结合关键词检索BM25和向量检索•重排序使用 Rerank 模型对初筛结果精排•查询改写用 LLM 改写用户问题提升召回率六、Embedding 实战构建语义搜索系统6.1 完整代码示例from openai import OpenAIimport numpy as npfrom typing import List, Tupleclient OpenAI()class SemanticSearch: def __init__(self, modeltext-embedding-3-small): self.model model self.documents [] self.embeddings [] def add_documents(self, docs: List[str]): 添加文档到索引 self.documents.extend(docs) # 批量获取 Embedding response client.embeddings.create( inputdocs, modelself.model ) for item in response.data: self.embeddings.append(item.embedding) def search(self, query: str, top_k: int 3) - List[Tuple[str, float]]: 语义搜索 # 获取查询的 Embedding query_response client.embeddings.create( inputquery, modelself.model ) query_embedding query_response.data[0].embedding # 计算相似度 similarities [] for i, doc_embedding in enumerate(self.embeddings): sim self._cosine_similarity(query_embedding, doc_embedding) similarities.append((self.documents[i], sim)) # 排序返回 Top-K similarities.sort(keylambda x: x[1], reverseTrue) return similarities[:top_k] def _cosine_similarity(self, a: List[float], b: List[float]) - float: a np.array(a) b np.array(b) return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))# 使用示例search_engine SemanticSearch()# 添加文档documents [ Transformer 是一种基于自注意力机制的神经网络架构, BERT 使用双向编码器来理解文本上下文, GPT 系列模型使用单向解码器进行文本生成, Word2Vec 是经典的词向量训练方法, RNN 和 LSTM 是处理序列数据的传统方法]search_engine.add_documents(documents)# 搜索results search_engine.search(什么是注意力机制)for doc, score in results: print(f[{score:.4f}] {doc})七、Embedding 技术演进趋势7.1 动态嵌入取代静态嵌入静态嵌入Word2Vec、GloVe为每个词生成固定向量无法区分同一词在不同上下文中的含义如「苹果公司」和「苹果水果」。动态嵌入Contextualized Embeddings根据上下文生成不同的向量表示已成为主流方案。7.2 N-gram Embedding美团 LongCat 团队在 2026 年初发布的 LongCat-Flash-Lite 模型中将超过 300 亿参数用于嵌入层通过 N-gram Embedding 捕捉短语级语义如热夏装 vs “夏天”在词表扩展的方式上实现了轻量化 MoE 的高效演进。7.3 多模态 EmbeddingCLIP 和 BLIP 等模型将文本和图像嵌入到共享向量空间实现跨模态检索如文本搜图。这类模型在电商推荐、图文匹配等场景中应用广泛。7.4 选择建议关键要点回顾Embedding 是语义的数值化将离散文本映射为连续向量语义相近的内容在向量空间中距离更近位置编码弥补了 Attention 的顺序盲区正弦余弦编码是经典方案RoPE 是当前主流余弦相似度是最常用的相似度度量只关注方向不关注长度适合文本语义匹配Embedding 模型选择要权衡效果和成本text-embedding-3-large 效果最好small 性价比高向量数据库是 RAG 系统的核心Embedding 向量数据库 LLM 知识增强的 AI 应用普通人如何抓住AI大模型的风口领取方式在文末为什么要学习大模型目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 大模型作为其中的重要组成部分 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 为各行各业带来了革命性的改变和机遇 。目前开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景其中应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过30%。随着AI大模型技术的迅速发展相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业人工智能大潮已来不加入就可能被淘汰。如果你是技术人尤其是互联网从业者现在就开始学习AI大模型技术真的是给你的人生一个重要建议最后只要你真心想学习AI大模型技术这份精心整理的学习资料我愿意无偿分享给你但是想学技术去乱搞的人别来找我在当前这个人工智能高速发展的时代AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料能够帮助更多有志于AI领域的朋友入门并深入学习。真诚无偿分享vx扫描下方二维码即可加上后会一个个给大家发【附赠一节免费的直播讲座技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等欢迎大家~】大模型全套学习资料展示自我们与MoPaaS魔泊云合作以来我们不断打磨课程体系与技术内容在细节上精益求精同时在技术层面也新增了许多前沿且实用的内容力求为大家带来更系统、更实战、更落地的大模型学习体验。希望这份系统、实用的大模型学习路径能够帮助你从零入门进阶到实战真正掌握AI时代的核心技能01教学内容从零到精通完整闭环【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块内容比传统教材更贴近企业实战大量真实项目案例带你亲自上手搞数据清洗、模型调优这些硬核操作把课本知识变成真本事02适学人群应届毕业生无工作经验但想要系统学习AI大模型技术期待通过实战项目掌握核心技术。零基础转型非技术背景但关注AI应用场景计划通过低代码工具实现“AI行业”跨界。业务赋能突破瓶颈传统开发者Java/前端等学习Transformer架构与LangChain框架向AI全栈工程师转型。vx扫描下方二维码即可【附赠一节免费的直播讲座技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等欢迎大家~】本教程比较珍贵仅限大家自行学习不要传播更严禁商用03入门到进阶学习路线图大模型学习路线图整体分为5个大的阶段04视频和书籍PDF合集从0到掌握主流大模型技术视频教程涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向新手必备的大模型学习PDF书单来了全是硬核知识帮你少走弯路不吹牛真有用05行业报告白皮书合集收集70报告与白皮书了解行业最新动态0690份面试题/经验AI大模型岗位面试经验总结谁学技术不是为了赚$呢找个好的岗位很重要07 deepseek部署包技巧大全由于篇幅有限只展示部分资料并且还在持续更新中…真诚无偿分享vx扫描下方二维码即可加上后会一个个给大家发【附赠一节免费的直播讲座技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等欢迎大家~】






总体吠)